Look Smarter With Git: Rewriting Your History

Intro
This blog post is co-authored by Nizar.
As developers, we are encouraged to commit code changes early and frequently. A benefit of which is being able to revert to previous states when needed. This luxury, however, can come at the expense of a rather messy Git history; one that communicates how the intended changes were reached rather than what they are.
This is considerably noticeable in projects with active main branches, a consequence of the additional merge commit to a feature branch's history every time upstream changes are incorporated into it. Which begs the question, should we strive for a more concise and readable history in favor of a truly representative one?
We believe that a Git history that makes it easy for others to follow and understand the history of a project is a preferable one, a history that focuses on communicating a series of coherent, and logically separated changes.
Luckily, Git provides us with the tools to do both. In this post, we present some of our favorite tools that we use to reorganize intermediate changes into coherent commits and in turn make the improvements we want to a project's history.
Git Reset
Git Reset is often used while working with our staging area; this area is where we add the changes that we commit when using git commit.
Git reset can be used to rewind history in two ways, by discarding our changes and by keeping them intact.
Hard Reset
A hard reset is used to rewind history and discard changes. That is, if we no longer wish to keep changes made in a previous commit, we can run git reset --hard HEAD~1 and have Git rewind our branch to the preceding commit.
Soft Reset
A soft reset works the same way as a hard reset except that it keeps our changes. That is, changes made in commits that we rewind will be kept in the staging area. This allows us to selectively pick the changes that we want into one or more new commits.
Git Add Patch
The Git Add command can be used to not only add entire files to our staging area, but to also selectively pick lines from one or more changed files.
The git add -p [file] command contains an optional argument for the path to a file which contains changes in our repository.
If no file path is provided, Git will work with every file in the repository that contains changes. That is, Git will iterate through all the changes and will, for each change, ask whether to add it to the staging area or not.
Git Rebase
Git Rebase is used to move one or more commits from one place in the Git history to another.
For example: Let's say that we have a project with a main branch and a feature branch, both of which have two commits added to them after the branching point as illustrated in the figure below.
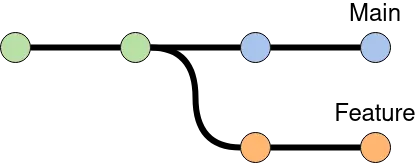
Regular Rebase
A regular rebase is often used instead of a merge. To illustrate how it works and how the two differ, we look at how a merge works.
When two branches are merged, a new commit is created. This new commit is the intersection point of two separate histories. If there are any conflicts between the two histories, they are resolved in the merge commit and added to the history.
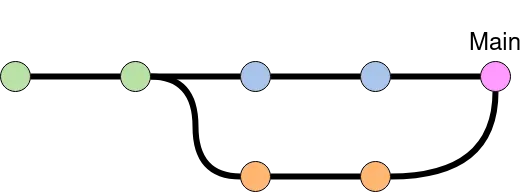
Rebasing achieves the same goal but does so in a different way. When a branch is rebased, its start in history is moved from one spot in history to another, most often in front of the last commit on the branch we would have merged with. That is, we place one branch after the other in history instead of intersecting two branches.
Conflicts are resolved during rebasing and commits containing conflicting changes are modified to no longer be in conflict, effectively removing the conflicts from history.

As such, a rebase creates a linear history, one that is easier to follow. This is also visible when viewing the history using a graphical tool; the history looks like a straight line rather than a set of intertwining parallel tracks.
Interactive Rebase
An interactive rebase allows us to take full control of the history. This is accomplished by invoking the git rebase -i <startpoint> command. startpoint here is a reference to a commit, such as a branch or a commit-SHA, in the history from where we want to start making changes.
Running the command creates a text file that is opened by an editor, allowing us to make changes to the commit history. Editing this file allows us to, among other things:
- Reorder commits.
- Remove a commit.
- Combine (squash) commits.
- Edit a commits' message.
- Stop a rebase process, start a shell, and edit the contents of a commit before proceeding.
Together, and with the tools and techniques described above, we are able to to reorder, combine, split, and edit commits to clean up the history. We can do this once our code is at a point where we think it is ready for for others to see.
When Not To Mess With History
It is important to know that you should never rebase a public branch. That is, you should not rewrite the branch history if someone else shares it. The main branch is an example of such a branch. Doing so will result in a situation that is tricky to resolve and leaves a confusing history.
That said, you are free to do so on your development branches before creating pull requests. In fact, and as discussed in this post, we believe that such efforts provide valuable improvements for everyone using the project.